Benchmark
Experimental Setup
We evaluate Cortex against several state-of-the-art open-source visuomotor policies on a bimanual manipulation platform. Our hardware consists of two Universal Robots UR5e arms, each equipped with a Robotiq 2F-140 parallel gripper. Visual observations are captured through fisheye cameras mounted on the end-effectors, providing egocentric views of the workspace. This setup presents significant challenges for learned policies, including coordinating dual-arm motion, handling the distortion inherent to fisheye optics, and generalizing across diverse manipulation primitives.
We design three benchmark tasks of increasing complexity to assess performance across different manipulation skills: object sorting, fine-grained part manipulation, and multi-step sequential tasks requiring both dexterous handling and semantic understanding.

Tasks
Shoebox
The shoebox task is a multi-step sequential manipulation challenge. The robot is presented with a closed shoebox and must: (1) open the box lid, (2) remove the packing paper and place it in the left bin, (3) extract one shoe and place it in the right bin, and (4) extract the remaining shoe and place it in the right bin. This task tests the system's capacity for long-horizon execution, handling deformable objects (paper), and manipulating articulated containers. Unlike the sorting tasks, we evaluate this task holistically, counting full success only when all steps are completed correctly.

Sorting Screws
This task requires fine-grained manipulation of small metal screws and other tooling scattered on a tabletop. The robot must pick up each screw and deposit it into the correct compartment of a multi-section toolbox. The challenge lies in precisely localizing and grasping small, reflective objects that may roll or shift during manipulation, and placing them into the correct compartments. Success demands accurate visual perception under challenging lighting conditions and precise gripper control. As with item sorting, we evaluate performance on a per-operation basis.

Sorting Items and Trash
In this task, the robot is presented with a cardboard box containing a mixture of everyday items and trash. The objective is to sort the contents by placing trash into a bin on the left side of the workspace and transferring items into a bin on the right. This task evaluates the system's ability to distinguish objects in a cluttered environment, classify object categories, plan efficient grasp sequences, and execute reliable pick-and-place operations. We report success rates at the level of individual sorting operations, where each object placement constitutes a single trial.

Data
Although Cortex transfers efficiently to new tasks due to extensive pre-training on our real-world deployment data, we collected a substantial number of demonstrations for each benchmark task to enable fair comparison with baseline methods.
| Task | Episodes | Hours |
|---|---|---|
| Shoebox | 2,900 | 8.1 hours |
| Sorting Screws | 3,100 | 8.2 hours |
| Sorting Items and Trash | 8,700 | 21 hours |
Models
We evaluate the following policies: π₀.₅ [1], Diffusion Policy [2], Cortex (ours), and RDT-2 [3]. All models are trained with equivalent computational budgets to ensure fair comparison. Models are trained in their original action and observation spaces to preserve transfer learning capabilities.
| Model | Training Compute | Observation Space | Action Space |
|---|---|---|---|
| Cortex | 200 GPU hours | Cartesian | Relative end-effector (translation + 6D rotation) |
| Diffusion Policy [2] | 200 GPU hours | Cartesian | Relative end-effector (translation + 6D rotation) |
| π₀.₅ [1] | 200 GPU hours | Absolute joint | Absolute joint |
| RDT-2 [3] | 200 GPU hours | Cartesian | Relative end-effector (translation + 6D rotation) |
Cortex, Diffusion Policy, and RDT-2 operate in Cartesian space with relative end-effector actions, predicting translational displacements and 6D rotation representations. In contrast, π₀.₅ uses absolute joint-space observations and actions, directly predicting target joint configurations.
For Diffusion Policy and π₀.₅, we use the LeRobot implementation [4]. For RDT-1B, we use the official implementation provided by the authors [5].
Experiments
We conduct extensive real-world experiments across all three benchmark tasks to evaluate Cortex against the baseline policies. For each task, we report quantitative success rates, analyze failure modes, and provide qualitative results through video demonstrations. All experiments are repeated across multiple trials with randomized initial conditions to ensure statistical significance.
Unrecoverable States and Human Interventions
Across all experiments, we track unrecoverable states, defined as execution states from which the policy cannot autonomously continue and human intervention is required to resume the rollout.
An unrecoverable state is recorded under any of the following conditions:
- Safety-critical collisions
The robot collides with the environment (items, bins, table), with itself, or with the other arm. In such cases, execution is automatically halted and the system is re-homed as needed before continuing the rollout.
- Persistent control deadlocks
The policy enters a repeated or oscillatory motion pattern (e.g., cycling through near-identical grasp attempts or micro-adjustments) without measurable task progress. These failures do not resolve through continued execution.
- Environment states outside the policy's recovery capability
The robot's actions change the scene such that the policy can no longer recover (e.g., severe object displacement, entanglement, or clutter accumulation). Human assistance is required to restore a workable configuration.
Recovery protocol
When an unrecoverable state occurs, we apply the minimum intervention needed to resume execution and allow the rollout to continue from the last recoverable state, rather than resetting the task from scratch. Concretely:
- Collisions: stop execution, re-home/restart as needed, and resume with the scene left as-is.
- Deadlocks / unrecoverable scene changes: lightly adjust the environment only to restore a recoverable configuration (e.g., reposition a bin or object), without undoing completed progress.
This metric therefore captures both safety interruptions and practical autonomy breakdowns under a realistic deployment protocol, while avoiding artificial penalties from full environment resets.
Experiment 1: Shoebox
Cortex
π₀.₅
Diffusion Policy
RDT-2
Setup
The shoebox task evaluates long-horizon, multi-step manipulation capabilities. The robot is presented with a closed shoebox and must execute a sequence of subtasks: (1) open the box lid, (2) remove the packing paper and place it in the left bin, and (3) extract both shoes and place them in the right bin. This task requires coordinating articulated object manipulation, handling deformable objects, and executing precise bimanual transfers.
Evaluation Protocol
- •Number of rollouts: 10 per policy, each rollout starts with a closed shoebox placed in front of the robot
- •Metrics: Full task success rate, per-subtask success rate, average completion time, average number of unrecoverable states per rollout
- •Randomization: Box orientation, paper configuration, shoe placement within box are varied between rollouts
- •Failure criteria: Failed lid opening, torn paper, dropped shoes, incomplete task execution
- •Scoring: Success and failure are counted holistically over the entire task; a rollout is considered successful only if all subtasks are completed correctly
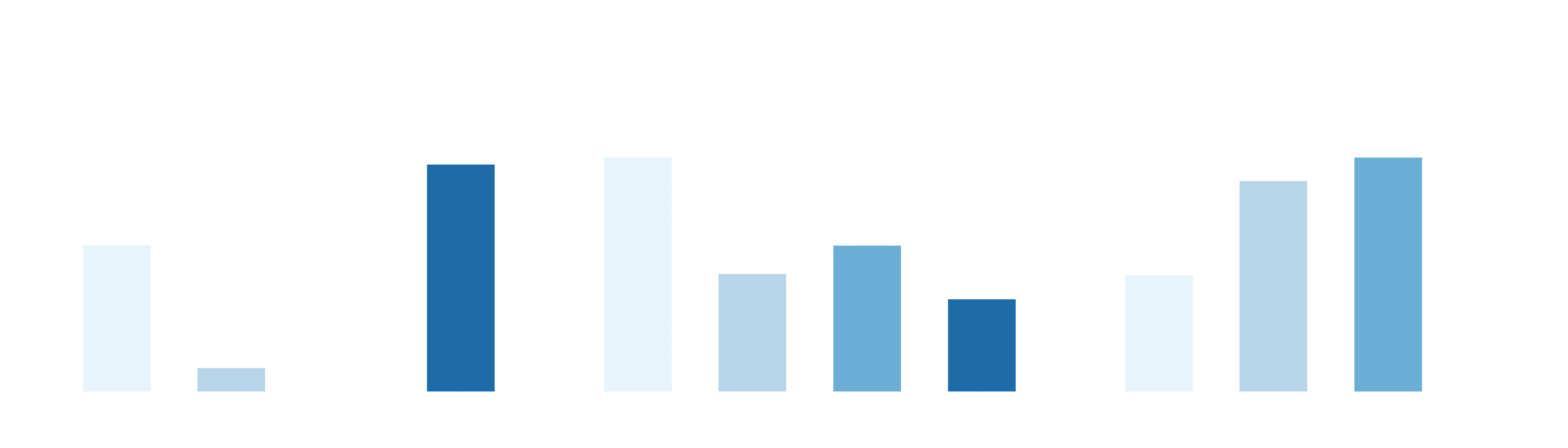
Figure 1 presents holistic success rates, average completion times, and the number of human interventions required for the shoebox task.
Cortex achieves the highest holistic success rate while also completing the task significantly faster than baseline methods, and does so without requiring human intervention across rollouts. This indicates strong temporal consistency and the ability to maintain task context across the full task sequence. As with the screw sorting task, this benchmark is trained with significantly fewer demonstrations, emphasizing Cortex's ability to transfer and scale to complex task structure with limited additional data. π₀․₅ achieves relatively high success at the subtask level but fails to complete the full task more frequently than Cortex and requires substantially longer execution times, frequently entering unrecoverable states that require intervention in later stages of the task. It is often able to progress through the early stages but struggles to adapt to scene changes introduced by prior actions, such as shifts in the box or object configurations. Diffusion Policy exhibits significantly lower success rates overall and is only marginally competitive, frequently failing during later stages such as shoe extraction due to unstable grasping and limited recovery from failed picks. RDT-2 never completes the full task and frequently enters unrecoverable states, preventing meaningful progress beyond the early stages.
These findings suggest that Cortex scales effectively to long-horizon manipulation tasks that require sustained coordination, robust recovery behavior, and minimal human intervention.
Experiment 2: Sorting Screws
Cortex
π₀.₅
Diffusion Policy
RDT-2
Setup
This experiment evaluates fine-grained manipulation capabilities by requiring the robot to sort screws scattered on a tabletop into the correct compartments of a toolbox.
Evaluation Protocol
- •Number of rollouts: 10 per policy, each rollout consists of sorting all screws scattered on the table into the toolbox
- •Metrics: Per-operation success rate (aggregated across all screws in all rollouts) average completion time, average number of unrecoverable states per rollout
- •Randomization: Screw positions and orientations are varied between rollouts
- •Failure criteria: Dropped screws, incorrect compartment placement, failed grasps
- •Scoring: Each individual screw placement is counted toward the overall success rate
.png&w=3840&q=75)
Figure 2 reports results for the fine-grained screw sorting task.
Cortex substantially outperforms all baseline methods, achieving near-perfect per-operation success while completing the task in the shortest average time. Cortex completes all rollouts without entering unrecoverable states, indicating reliable autonomous execution in a precision-critical manipulation setting. Among the baseline policies, this task exhibits the largest performance gap relative to Cortex. π₀․₅ attains moderate success and remains the strongest baseline in terms of per-operation task completion; however, it exhibits limited precision when manipulating small objects of varying shapes and enters unrecoverable states more frequently than Diffusion Policy on this task. Diffusion Policy achieves lower success rates than π₀․₅ but demonstrates comparatively greater stability, while RDT-2 fails almost entirely, with zero successful placements and multiple unrecoverable states per rollout, indicating limited robustness to small-object manipulation.
These results highlight Cortex's effectiveness in precision-critical manipulation scenarios, where small errors can alter object pose or position and compound task difficulty in subsequent steps. Notably, this performance is achieved despite substantially fewer task-specific demonstrations than in the sorting items and trash task, highlighting rapid adaptation in a more data-limited setting.
Experiment 3: Sorting Items and Trash
Cortex
π₀.₅
Diffusion Policy
RDT-2
Setup
In this experiment, the robot must sort a mixture of items and trash from a central cardboard box into two target bins. The left bin is designated for trash (e.g., crumpled paper, empty wrappers, used napkins), while the right bin is designated for reusable items (e.g., toys, tools, office supplies). Each trial begins with 10–15 objects randomly placed in the source box. We evaluate performance at the granularity of individual pick-and-place operations, counting each object placement as a separate trial.
Evaluation Protocol
- •Number of rollouts: 10 per policy, each rollout consists of sorting a full bin of mixed items and trash
- •Metrics: Per-operation success rate (aggregated across all objects in all rollouts), category classification accuracy, cycle time per object, average task completion time, average number of unrecoverable states per rollout
- •Randomization: Object types, quantities, positions, and orientations are randomized between rollouts
- •Failure criteria: Dropped objects, incorrect bin placement, grasp failures, collisions
- •Scoring: Each individual sorting operation is counted toward the overall success rate. Any sorting operation that requires human intervention is counted as a failure.
.png&w=3840&q=75)
Figure 3 shows the per-operation success rate, average completion time, and the number of human interventions required across the sorting items and trash task.
Cortex achieves the highest success rate among evaluated methods while also exhibiting the shortest average task duration. Cortex completes all rollouts without any human intervention, indicating that it is able to reliably execute repeated pick-and-place operations end to end without sacrificing efficiency. This task also benefits from the largest amount of task-specific demonstration data, which contributes to comparatively stronger baseline performance relative to the other benchmarks. In contrast, all baseline policies require human intervention in every rollout to complete the task. π₀․₅ achieves higher success rates than the remaining baseline policies on this task, but fails to complete the full task within the 15-minute execution limit in all runs. Its dominant failure mode is repeated local replanning around failed grasp attempts, leading to prolonged execution and more frequent entry into unrecoverable states compared to Cortex. Diffusion Policy attains a moderate success rate but exhibits greater instability; its failures are primarily driven by grasp instability and object drops. RDT-2 achieves significantly lower success rates than all other evaluated methods and frequently enters unrecoverable states, reflecting limited robustness and ineffective recovery behavior during repeated operations. Like π₀․₅, both Diffusion Policy and RDT-2 also reach the 15-minute execution limit in all runs without completing the full task.
Overall, these results indicate that Cortex is qualitatively different from the baseline policies: it reliably completes the task autonomously, whereas baseline methods depend on repeated human intervention to finish execution. Cortex therefore provides a substantially stronger balance between reliability and throughput in cluttered, repetitive manipulation settings.
Summary
Across all three benchmarks, Cortex consistently achieves higher success rates and shorter execution times than the evaluated baseline policies. π₀.₅ generally attains the strongest performance among the baselines at the subtask level but requires substantially longer execution times and frequently fails to complete tasks end to end, particularly in long-horizon settings. Diffusion Policy exhibits lower overall success, while RDT-2 consistently fails to complete complex tasks. All three baseline policies enter unrecoverable states more frequently than Cortex, reducing overall reliability and contributing to task failure and increased reliance on human intervention.
Cortex maintains strong performance across all three benchmarks, consistently completing tasks autonomously without human intervention, demonstrating strong transfer learning by rapidly adapting to new task structures and object interactions. Overall, these results show that Cortex, being pretrained on real-world data, is able to generalize much faster and more reliable to new tasks. With limited amount of fine-tuning data, Cortex is able to achieve success rates beyond 90% on all tasks. This allows to us to go live with a strong baseline model and achieve 99% after deployment with in-domain data.
References
[1] Physical Intelligence, K. Black, N. Brown, et al., "π₀.₅: A Vision-Language-Action Model with Open-World Generalization," arXiv preprint arXiv:2504.16054, 2025. https://arxiv.org/abs/2504.16054
[2] C. Chi, S. Feng, Y. Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, "Diffusion Policy: Visuomotor Policy Learning via Action Diffusion," in Proceedings of Robotics: Science and Systems (RSS), 2023. https://arxiv.org/abs/2303.04137
[3] S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu, "RDT-1B: A Diffusion Foundation Model for Bimanual Manipulation," in Proceedings of the International Conference on Learning Representations (ICLR), 2025. https://arxiv.org/abs/2410.07864
[4] Hugging Face, "LeRobot: Making AI for Robotics more accessible with end-to-end learning," https://github.com/huggingface/lerobot
[5] Tsinghua University, "RoboticsDiffusionTransformer," https://github.com/thu-ml/RoboticsDiffusionTransformer
Robotics Diffusion Transformer — A diffusion-based foundation model architecture designed for bimanual robotic manipulation tasks, using transformer networks for action prediction.